- Published on
多模态语言模型:探索 Gemini Pro 和 Streamlit 的神奇组合
- Authors

- Name
- NoOne
如果你还没有听说,谷歌在 2023 年 12 月 6 日推出了他们的多模态大语言模型。这个模型基于多模态原理开发,可以能够处理和理解包括文本、代码、音频、图像和视频在内的各种数据类型。
Gemini 的发布一周后,该模型对公众开放,我们可以在这里试用。最初发布的模型有三个版本,但目前我们可以访问的是 Gemini Pro 版本。我们可以使用 Gemini Pro 文本模型或视觉模型的 API。
有了 API,我们可以开始实验并创造一些独特的东西。因此,这篇文章将教你如何使用 Gemini Pro 和 Streamlit 创建一个简单的多模态大语言模型Dashboard。
Gemini API
在开始之前,让我们先熟悉一下 Gemini API。在这一部分,我们将介绍模型 API 的主要用法以及如何获得输出。
首先,我们必须安装 Google 生成式 AI 包来访问 Gemini API。我建议你使用虚拟环境,因为我们不想破坏我们的基础环境。
pip install google-generativeai
成功安装包后,我们需要 Google API 密钥。你可以访问Google Makersuite并申请密钥。
为了简化操作,我们通过传递密钥到 .configure 函数来设置我们的 API 密钥。
import google.generativeai as genai
genai.configure(api_key=GOOGLE_API_KEY)
接下来,我们将尝试使用 Gemini 模型。如我上文提到的,目前我们可以使用两个模型:
gemini-pro:仅限文本提示的模型。gemini-pro-vision:用于文本和图像的多模态模型。
我们来尝试使用 gemini-pro 模型生成文本输入。最简单的形式就是将提示传递给模型,类似于下面的代码。
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("What is the use of eyes?")
print(response.text)

来自 Gemini Pro Vision 模型的返回
接下来,让我们将图像和文本输入传递给 gemini-pro-vision 模型并生成文本回应。在这个例子中,我会输入我们的封面图片。
img = Image.open('image.jpg')
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
print(response.text)

来自 Gemini Pro Vision 模型的返回
我们也可以添加我们的提示与图像数据输入,以生成特定的文本输出。
img = Image.open('image.jpg')
model = genai.GenerativeModel('gemini-pro-vision')
prompt = "What is the color of this image and the color of the text?"
response = model.generate_content([prompt, img])
print(response.text)

model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=[])
然后,使用以下代码尝试整个对话。
model = genai.GenerativeModel('
gemini-pro')
chat = model.start_chat(history=[])
response = chat.send_message("What is the use of the eyes?", stream = True)
response.resolve()
print(response.text)
response = chat.send_message("Summary the previous passages to me in one sentence", stream = True)
response.resolve()
print(response.text)
print(chat.history)
我们使用 .resolve 函数让模型在我们继续之前完成处理。同时,我们将 stream 参数设置为 true 以流式传输聊天。下图是上述对话的聊天记录。

然而,截至本文撰写时,gemini-pro-vision 模型还无法启动多轮对话。这意味着你无法将视觉模型转换为对话型模型。
最后,我们可以使用 generation_config 参数调整模型参数。例如,我们更改最大 Token 输出和模型参数。
response = model.generate_content('What is the use of the eyes?',
generation_config=genai.types.GenerationConfig(max_output_tokens=50,
temperature=0.5))

使用 Streamlit 构建 LLM 应用
本教程的其余部分是关于结构化和将 Streamlit 组件与 Gemini API 模型结合起来。如果你还没有安装包,可以使用以下代码。
pip install streamlit
首先,我们将设置信息页面以请求 Google API 密钥。我们这样做是为了在输入表单中提供密钥之前不会继续。
import streamlit as st
from PIL import Image
import google.generativeai as genai
st.set_page_config(page_title="Gemini Pro with Streamlit",page_icon="♊")
st.write("Welcome to the Gemini Pro Dashboard. You can proceed by providing your Google API Key")
with st.expander("Provide Your Google API Key"):
google_api_key = st.text_input("Google API Key", key="google_api_key", type="password")
if not google_api_key:
st.info("Enter the Google API Key to continue")
st.stop()
genai.configure(api_key=google_api_key)
我将上述代码放在名为 home.py 的文件中,并使用以下命令在 CLI 中启动应用。
streamlit run home.py
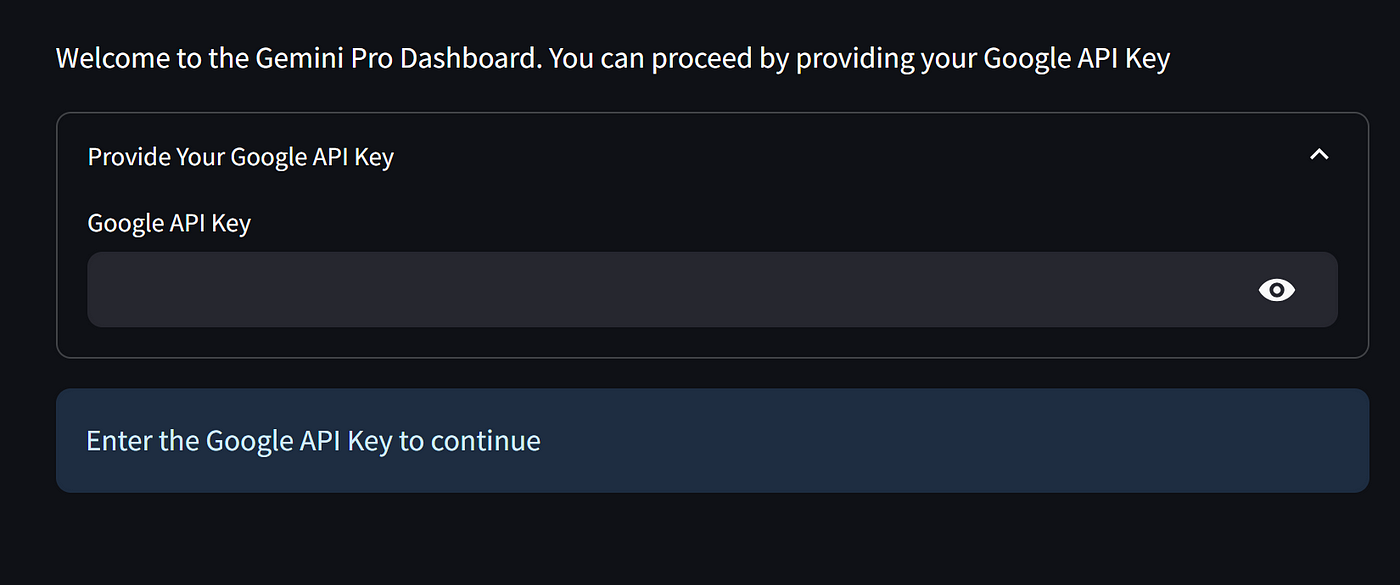
我们创建了一个简单的 Google API 密钥表单,用于接收文本输入,并将其放在可随时关闭的展开表单中。此外,信息会阻止任何活动,直到你提供 API 密钥。
接下来,我们将开发Dashboard侧边栏作为获取所有必要信息的地方。整个代码的初始化过程如下:
st.title("Gemini Pro with Streamlit Dashboard")
with st.sidebar:
option = st.selectbox('Choose Your Model',('gemini-pro', 'gemini-pro-vision'))
if 'model' not in st.session_state or st.session_state.model != option:
st.session_state.chat = genai.GenerativeModel(option).start_chat(history=[])
st.session_state.model = option
st.write("Adjust Your Parameter Here:")
temperature = st.number_input("Temperature", min_value=0.0, max_value= 1.0, value =0.5, step =0.01)
max_token = st.number_input("Maximum Output Token", min_value=0, value =100)
gen_config = genai.types.GenerationConfig(max_output_tokens=max_token,temperature=temperature)
st.divider()
st.markdown("<span ><font size=1>Connect With Me</font></span>",unsafe_allow_html=True)
"[Linkedin](https://www.linkedin.com/in/cornellius-yudha-wijaya/)"
"[GitHub](https://github.com/cornelliusyudhawijaya)"
st.divider()
upload_image = st.file_uploader("Upload Your Image Here", accept_multiple_files=False, type = ['jpg', 'png'])
if upload_image:
image = Image.open(upload_image)
st.divider()
if st.button("Clear Chat History"):
st.session_state.messages.clear()
通过添加上述代码,您的 Streamlit Dashboard 会是下面这样。
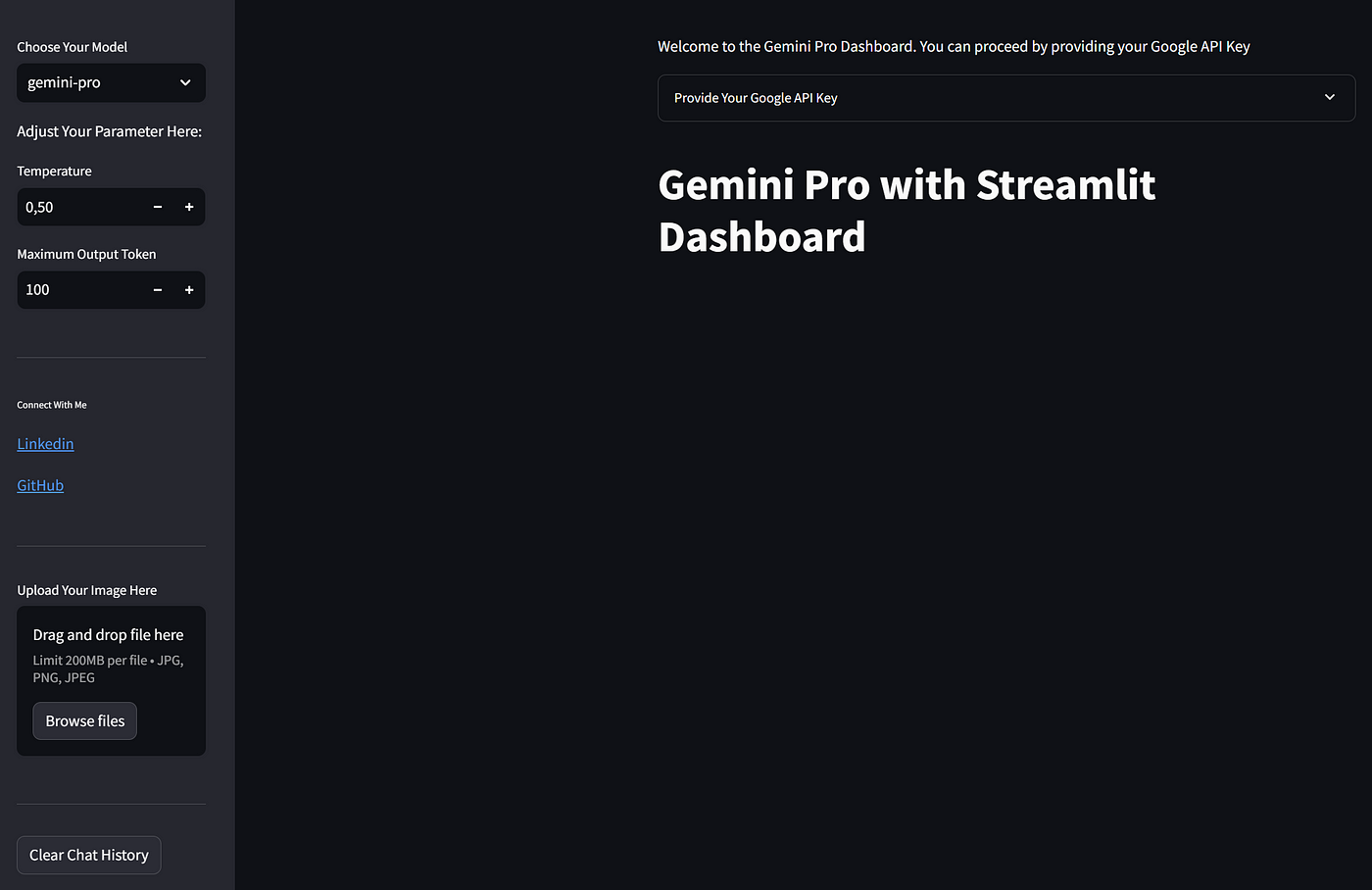
那么,上述代码中发生了什么?让我来解释一些重要的部分。
对于以下代码,我们为用户提供了一个选择框来选择他们想要使用的模型。
option = st.selectbox('Choose Your Model',('gemini-pro', 'gemini-pro-vision'))
if 'model' not in st.session_state or st.session_state.model != option:
st.session_state.chat = genai.GenerativeModel(option).start_chat(history=[])
st.session_state.model = option
同时,我将模型选择和对象 st.session_state 存储起来,这样我们的模型在运行应用程序时不会不断重置。Streamlit 在我们做某事时会运行整个脚本,所以我们需要一个在会话期间保存信息完整的容器。
然后,以下代码是为您想传递给模型的参数。
st.write("Adjust Your Parameter Here:")
temperature = st.number_input("Temperature", min_value=0.0, max_value= 1.0, value =0.5, step =0.01)
max_token = st.number_input("Maximum Output Token", min_value=0, value =100)
gen_config = genai.types.GenerationConfig(max_output_tokens=max_token,temperature=temperature)
由于我们想要使用 Gemini Pro Vision 模型进行多模态操作,我们需要初始化上传图像数据的选项。
upload_image = st.file_uploader("Upload Your Image Here", accept_multiple_files=False, type = ['jpg', 'png'])
if upload_image:
image = Image.open(upload_image)
最后,只是清除聊天记录并不断重置到开场对话的选项。
if st.button("Clear Chat History"):
st.session_state.messages.clear()
st.session_state["messages"] = [{"role": "assistant", "content": "Hi there. Can I help you?"}]
解释完侧边栏部分后,我们现在将聊天对话应用程序引入 Streamlit Dashboard。 为此,我们将使用以下代码。
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "Hi there. Can I help you?"}]
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
if upload_image:
if option == "gemini-pro":
st.info("Please Switch to the Gemini Pro Vision")
st.stop()
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
response=st.session_state.chat.send_message([prompt,image],stream=True,generation_config = gen_config)
response.resolve()
msg=response.text
st.session_state.chat = genai.GenerativeModel(option).start_chat(history=[])
st.session_state.messages.append({"role": "assistant", "content": msg})
st.image(image,width=300)
st.chat_message("assistant").write(msg)
else:
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
response=st.session_state.chat.send_message(prompt,stream=True,generation_config = gen_config)
response.resolve()
msg=response.text
st.session_state.messages.append({"role": "assistant", "content": msg})
st.chat_message("assistant").write(msg)
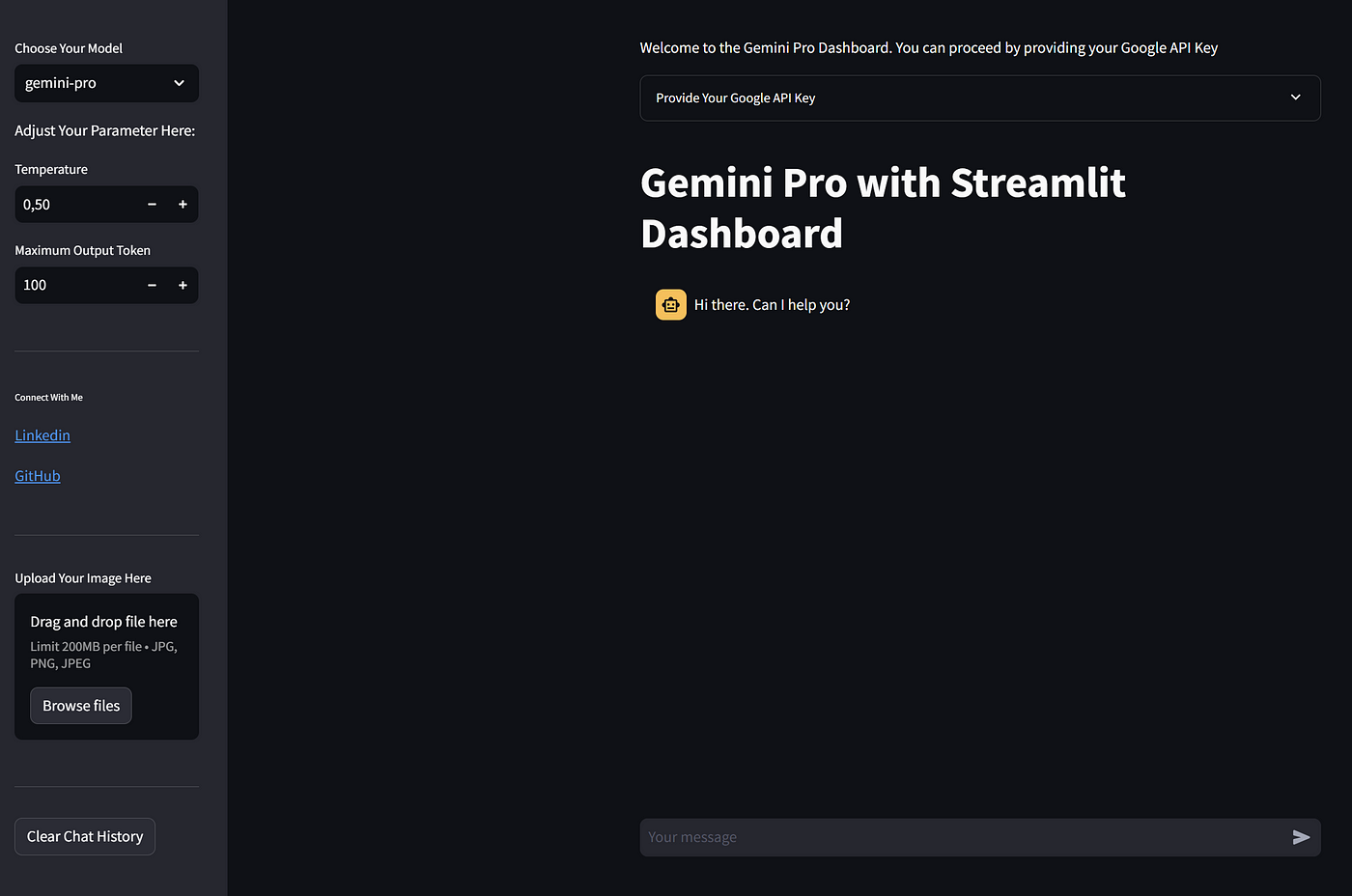
这就是我们的 Gemini Pro Dashboard应用程序与 Streamlit 的整体结构。让我再次解释一下我们的代码中发生了什么。
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "Hi there. Can I help you?"}]
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
在这一部分,我们设置了会话状态以存储所有发生的对话。此外,上述代码将是启动首次聊天并随后保持历史记录的代码。
然后,我们根据是否上传图片进行了条件分割。我们这样做是因为模型会根据您是否输入图像而有所不同。以下代码是我们上传图片时的情况。
if upload_image:
if option == "gemini-pro":
st.info("Please Switch to the Gemini Pro Vision")
st.stop()
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
response=st.session_state.chat.send_message([prompt,image],stream=True,generation_config = gen_config)
response.resolve()
msg=response.text
st.session_state.chat = genai.GenerativeModel(option).start_chat(history=[])
st.session_state.messages.append({"role": "assistant", "content": msg})
st.image(image,width=300)
st.chat_message("assistant").write(msg)
我们在上述代码中设置了一个条件,只有在模型是 Gemini Pro Vision 时才会运行,因为如果我们提供了图像输入,Gemini Pro 模型会出错。
上述代码中在所有条件都满足后发生的事情是,当我们输入聊天信息时,它会被存储在 prompt 变量中,然后用于随后的对话活动。此外,我们每次都会重置模型,因为 Gemini Pro Vision 模型不能进行多轮聊天。
这与以下代码类似,但适用于 Gemini Pro 模型。
else:
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
response=st.session_state.chat.send_message(prompt,stream=True,generation_config = gen_config)
response.resolve()
msg=response.text
st.session_state.messages.append({"role": "assistant", "content": msg})
st.chat_message("assistant").write(msg)
一切准备就绪,让我们测试一下我们的应用程序,看看它是否有效。让我们尝试视觉模型,看看它们的功能。
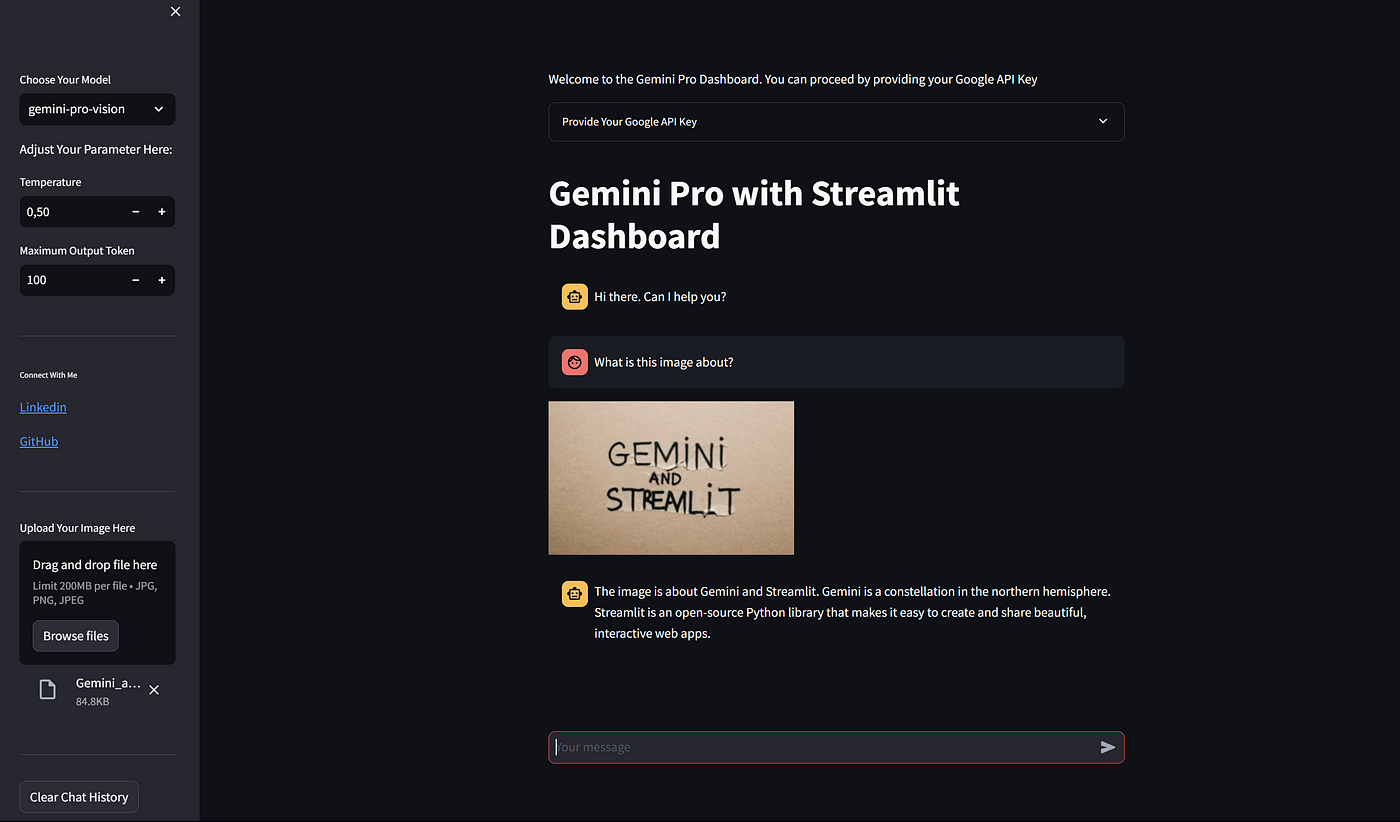
上图是Streamlit Dashboard与视觉模型。
它运行良好。让我们看看 Gemini Pro 模型是否能处理多轮对话。
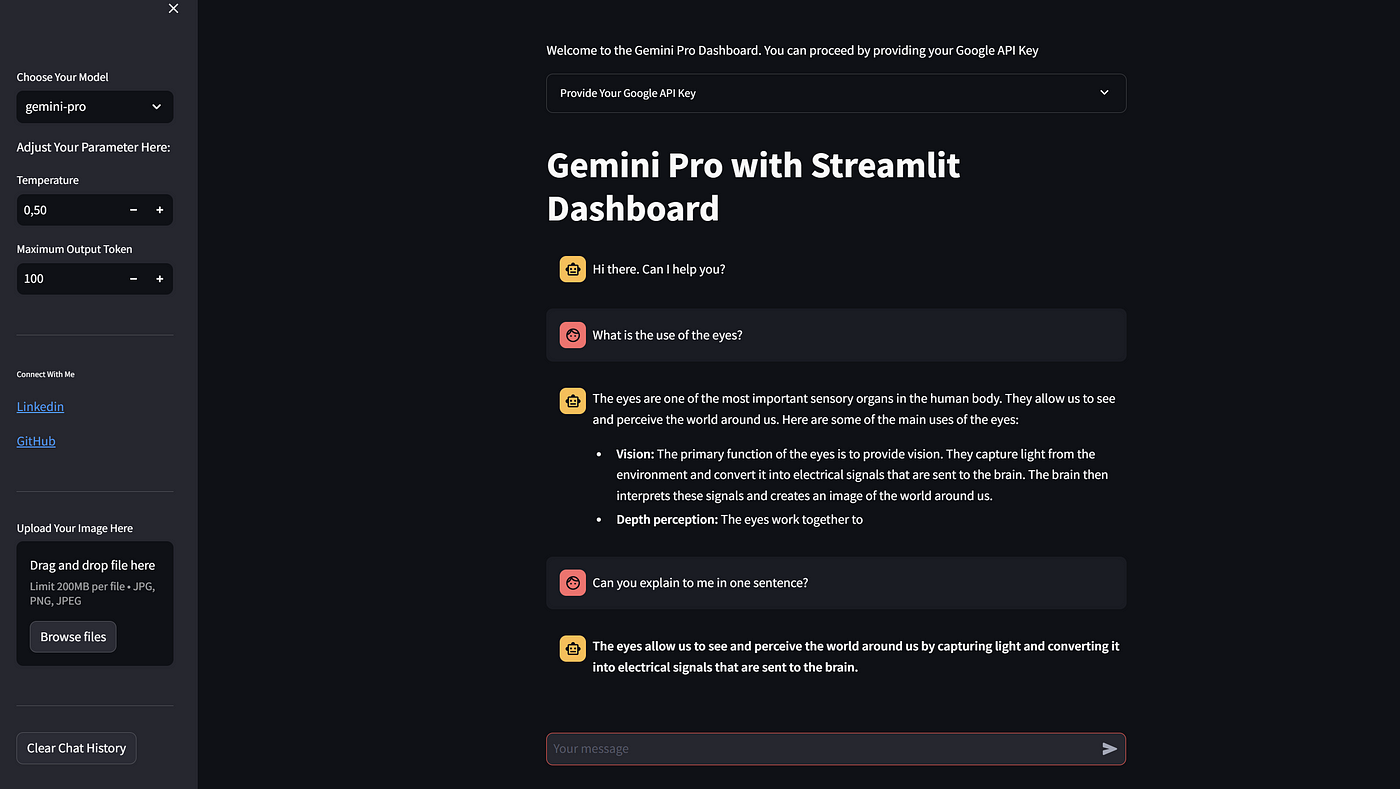
上图是与 Gemini Pro 的多轮对话。
该应用程序可以与 Gemini Pro 进行多轮对话。一切都运行顺利。
这就是本教程的全部内容。您可以随时调整代码以获得更好的布局或格式,或尝试您认为合适的其他模型。
结论
Gemini Pro 是 Google 团队的最新大语言模型,它展示了令人充满希望的结果。在这篇文章中,我们使用 Google 团队提供的公共 API 来创建我们的大语言模型多模态 Streamlit Dashboard。
Share this content